大數(shù)據(jù)工程師手冊 全面系統(tǒng)的掌握必備知識與工具
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,大數(shù)據(jù)工程師已成為技術(shù)領(lǐng)域的關(guān)鍵角色。他們負(fù)責(zé)設(shè)計(jì)、構(gòu)建和維護(hù)能夠處理海量數(shù)據(jù)的基礎(chǔ)設(shè)施與系統(tǒng),是連接數(shù)據(jù)源與商業(yè)價(jià)值的橋梁。本手冊旨在為有志于成為大數(shù)據(jù)工程師或希望系統(tǒng)提升技能的開發(fā)者提供一份全面的指南,涵蓋從基礎(chǔ)概念到核心工具,再到實(shí)戰(zhàn)開發(fā)的完整知識體系。
一、 大數(shù)據(jù)基礎(chǔ)與核心概念
成為一名合格的大數(shù)據(jù)工程師,首先需要建立堅(jiān)實(shí)的理論基礎(chǔ)。這包括理解大數(shù)據(jù)的核心特征(4V或5V:Volume體量、Velocity速度、Variety多樣性、Veracity準(zhǔn)確性、Value價(jià)值),以及相關(guān)的處理范式。
- 分布式系統(tǒng)原理:大數(shù)據(jù)處理的基石。需要理解分布式計(jì)算、存儲、協(xié)調(diào)和容錯(cuò)的基本原理,如CAP定理、一致性模型、共識算法(如Paxos、Raft)等。
- 數(shù)據(jù)處理范式:掌握批處理與流處理的區(qū)別與聯(lián)系。批處理適用于對海量歷史數(shù)據(jù)進(jìn)行離線分析,而流處理則專注于實(shí)時(shí)或近實(shí)時(shí)數(shù)據(jù)的連續(xù)處理。理解Lambda架構(gòu)和Kappa架構(gòu)等經(jīng)典設(shè)計(jì)模式。
二、 核心技能棧與必備工具
大數(shù)據(jù)工程師的技能棧可以概括為“一基、三核、多工具”。
- 編程基礎(chǔ)(一基):
- Java/Scala/Python:Java是Hadoop生態(tài)的基石;Scala是Spark的首選語言,函數(shù)式編程特性在處理數(shù)據(jù)時(shí)優(yōu)勢明顯;Python則以其簡潔和豐富的數(shù)據(jù)科學(xué)庫(如Pandas, NumPy)在數(shù)據(jù)分析、機(jī)器學(xué)習(xí)和快速原型開發(fā)中占據(jù)重要地位。扎實(shí)掌握至少一門是入門的關(guān)鍵。
- 三大核心技術(shù)棧(三核):
- 存儲層:理解分布式文件系統(tǒng)(如HDFS)和NoSQL數(shù)據(jù)庫(如HBase, Cassandra)的原理與應(yīng)用場景。數(shù)據(jù)湖(如基于HDFS或云原生對象存儲)和數(shù)據(jù)倉庫(如Hive, ClickHouse, Snowflake)的概念與選型也至關(guān)重要。
- 計(jì)算層:
- 批處理:Apache Spark是當(dāng)前事實(shí)上的標(biāo)準(zhǔn),需精通其RDD/DataFrame/Dataset API、執(zhí)行計(jì)劃優(yōu)化、內(nèi)存管理等。經(jīng)典的MapReduce(Hadoop)原理仍需了解。
- 流處理:Apache Flink以其先進(jìn)的流計(jì)算理念(如事件時(shí)間、狀態(tài)管理)成為主流;Apache Kafka Streams和Spark Streaming也是重要選項(xiàng)。理解流處理的核心概念,如時(shí)間窗口、水位線、Exactly-Once語義等。
- 資源管理與調(diào)度:YARN是Hadoop生態(tài)的傳統(tǒng)資源管理器;Kubernetes正成為云原生時(shí)代統(tǒng)一編排和部署大數(shù)據(jù)應(yīng)用的新標(biāo)準(zhǔn),需要掌握其基本概念與運(yùn)維。
- 關(guān)鍵輔助工具(多工具):
- 消息隊(duì)列/日志收集:Apache Kafka,作為高吞吐的分布式消息系統(tǒng),是大數(shù)據(jù)流水線的“中樞神經(jīng)”,用于解耦數(shù)據(jù)生產(chǎn)與消費(fèi)。
- 工作流調(diào)度:Apache Airflow或DolphinScheduler,用于編排復(fù)雜的數(shù)據(jù)處理任務(wù)依賴關(guān)系,實(shí)現(xiàn)自動(dòng)化調(diào)度。
- 數(shù)據(jù)攝取與同步:Sqoop(關(guān)系數(shù)據(jù)庫與HDFS之間)、Flume/Canal(日志/增量數(shù)據(jù)采集)、DataX、Debezium等。
- 集群管理與監(jiān)控:Ambari, Cloudera Manager(商業(yè)版)或自行搭建的Prometheus + Grafana監(jiān)控體系。
三、 從開發(fā)到實(shí)戰(zhàn):基礎(chǔ)軟件開發(fā)實(shí)踐
大數(shù)據(jù)工程師不僅是工具的運(yùn)用者,更是系統(tǒng)的構(gòu)建者。基礎(chǔ)軟件開發(fā)能力是區(qū)分高級工程師與普通用戶的關(guān)鍵。
- 設(shè)計(jì)與編碼:
- 模塊化與可復(fù)用性:將數(shù)據(jù)處理邏輯封裝成獨(dú)立的、可測試的模塊或函數(shù)。
- 配置化驅(qū)動(dòng):避免硬編碼,將環(huán)境變量、連接參數(shù)、業(yè)務(wù)規(guī)則等抽取為配置文件,提高系統(tǒng)的靈活性和可維護(hù)性。
- 代碼規(guī)范與質(zhì)量:遵循團(tuán)隊(duì)的編程規(guī)范,善用單元測試(如JUnit, pytest)和集成測試保證代碼質(zhì)量。理解并使用設(shè)計(jì)模式解決常見架構(gòu)問題。
- 性能調(diào)優(yōu):
- 數(shù)據(jù)傾斜處理:這是分布式計(jì)算中最常見的問題之一,需要掌握使用加鹽、雙重聚合等策略來應(yīng)對。
- 資源優(yōu)化:根據(jù)任務(wù)特性合理設(shè)置Executor數(shù)量、內(nèi)存、CPU核心數(shù)等參數(shù)。理解并優(yōu)化Spark的Shuffle過程、存儲級別選擇。
- SQL與執(zhí)行計(jì)劃:對于Hive/Spark SQL,能夠閱讀和分析執(zhí)行計(jì)劃,通過優(yōu)化SQL寫法、建立合適的分區(qū)與分桶、使用合適的Join策略來提升性能。
- 數(shù)據(jù)質(zhì)量與治理:
- 在數(shù)據(jù)流水線的關(guān)鍵節(jié)點(diǎn)設(shè)計(jì)數(shù)據(jù)質(zhì)量檢查規(guī)則,如非空校驗(yàn)、唯一性校驗(yàn)、數(shù)值范圍校驗(yàn)等。
- 實(shí)現(xiàn)數(shù)據(jù)血緣追蹤,記錄數(shù)據(jù)的來源、轉(zhuǎn)換過程與去向,便于問題排查和影響分析。
- 關(guān)注數(shù)據(jù)安全與隱私保護(hù),實(shí)施數(shù)據(jù)脫敏、訪問控制等策略。
- 部署與運(yùn)維:
- 容器化:使用Docker將應(yīng)用及其依賴打包,實(shí)現(xiàn)環(huán)境一致性。
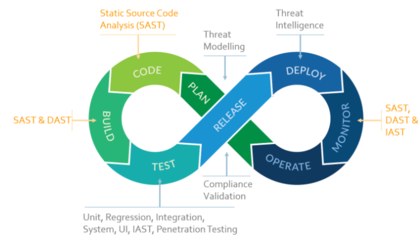
- CI/CD:建立持續(xù)集成/持續(xù)部署流水線(如使用Jenkins, GitLab CI),自動(dòng)化代碼檢查、測試、構(gòu)建和部署過程。
- 可觀察性:在代碼中埋點(diǎn),記錄關(guān)鍵指標(biāo)和日志,與監(jiān)控系統(tǒng)聯(lián)動(dòng),實(shí)現(xiàn)問題的快速定位與預(yù)警。
四、 學(xué)習(xí)路徑與持續(xù)成長
大數(shù)據(jù)技術(shù)生態(tài)日新月異。建議的學(xué)習(xí)路徑是:先深度,后廣度。首先選擇一個(gè)核心領(lǐng)域(如Spark或Flink)深入鉆研,理解其內(nèi)部原理和最佳實(shí)踐,構(gòu)建起處理某類問題(批或流)的完整知識閉環(huán)。然后橫向擴(kuò)展,了解生態(tài)中的其他組件,并關(guān)注云原生(如Kubernetes上的Spark/Flink)、湖倉一體、實(shí)時(shí)數(shù)倉等前沿趨勢。
積極參與開源社區(qū),閱讀優(yōu)秀項(xiàng)目的源代碼,在實(shí)踐中不斷解決真實(shí)場景下的復(fù)雜問題,是成長為一名卓越大數(shù)據(jù)工程師的必經(jīng)之路。記住,工具和技術(shù)會演變,但處理海量數(shù)據(jù)的核心思想、系統(tǒng)設(shè)計(jì)能力和扎實(shí)的工程實(shí)踐功底,才是你職業(yè)生涯中最寶貴的財(cái)富。
如若轉(zhuǎn)載,請注明出處:http://www.qpdn.com.cn/product/68.html
更新時(shí)間:2026-01-07 23:42:17